

Xiaolong Han
Ph.D. student at the University of Surrey
Ph.D. Student in Computer Science
Xiaolong Han
I am a Ph.D. student at the University of Surrey, advised by Prof. Ferrante Neri and Assistant Prof. Lu Yin.
My work focuses on parameter-centric machine learning: how model weights can be searched, analyzed, represented, and generated. I am currently most interested in weight space learning, neural architecture search, and functional representations for scientific data, and I actively collaborate with Zehong Wang on related problems.
My recent work asks three connected questions: how to search neural architectures more reliably, how to organize model weights into useful representations, and how to generate neural functions directly for structured domains such as molecules. I am particularly interested in methods that are efficient enough to reuse pretrained models rather than retraining from scratch.
Featured Projects

A Survey of Weight Space Learning: Understanding, Representation, and Generation
This survey organizes weight space learning into three axes: understanding, representation, and generation. It provides a unified map of how pretrained weights can be analyzed as structured objects and reused across retrieval, editing, federated learning, neural architecture search, and neural function generation.
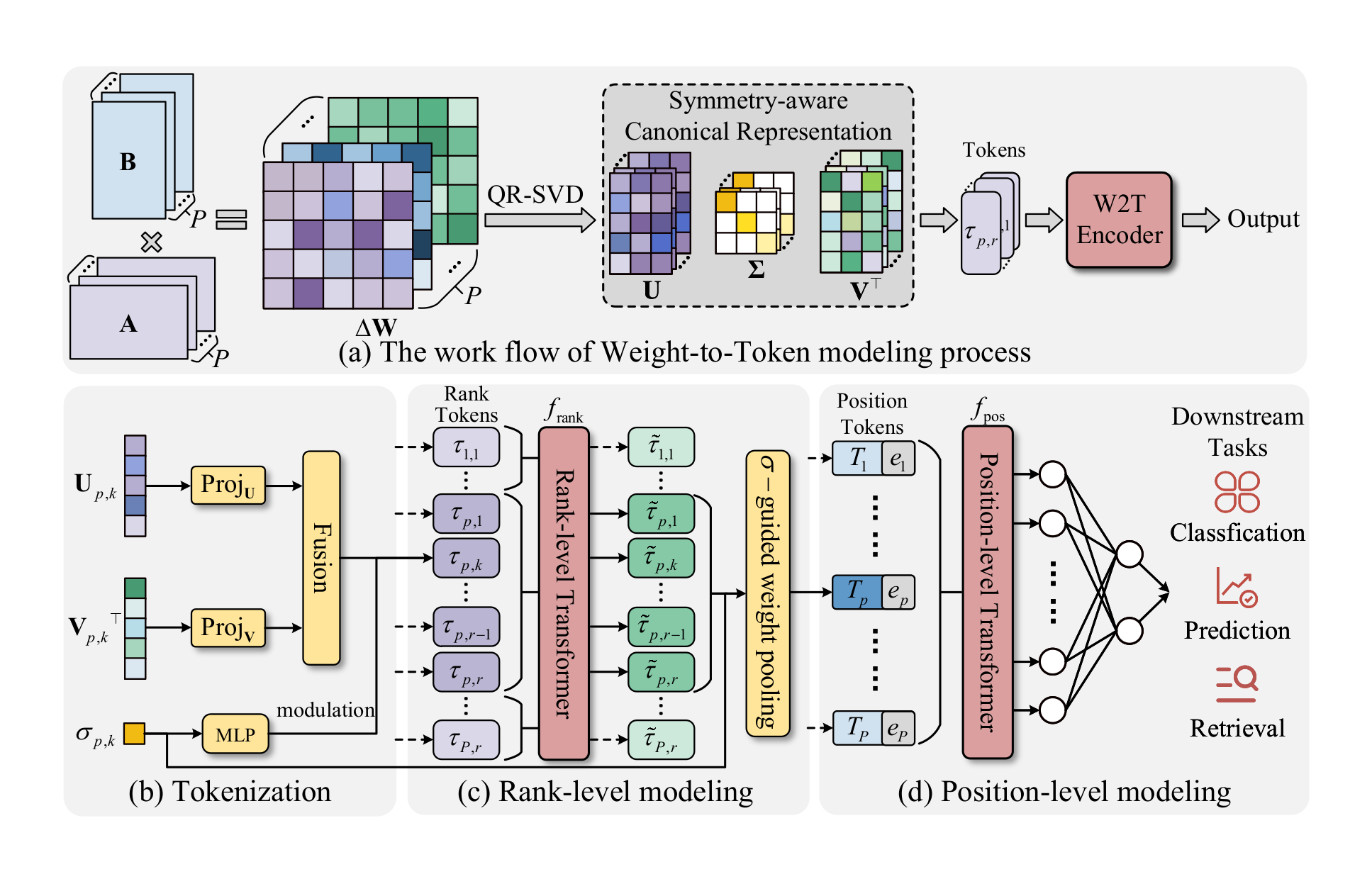
W2T: LoRA Weights Already Know What They Can Do
W2T asks whether LoRA checkpoints can be understood directly from their weights, without training data or base-model inference. It resolves LoRA factorization ambiguity with a symmetry-aware QR-SVD canonicalization, then tokenizes rank-wise components with a transformer encoder for attribute classification, performance prediction, adapter retrieval, and transfer across LoRA collections.

Molecular Representations in Implicit Functional Space via Hyper-Networks
MolField models molecules in implicit functional space rather than fixed graph embeddings. The framework combines SE(3)-aware canonicalization, structured weight tokenization, and a transformer hyper-network to generate task-conditioned neural fields for molecular dynamics, property prediction, and related downstream tasks.

SaDENAS: A Self-adaptive Differential Evolution Algorithm for Neural Architecture Search
SaDENAS revisits continuous evolutionary NAS through self-adaptive differential evolution. It balances local exploitation and global exploration in architecture-encoding space to reduce premature convergence and the small-model trap that can dominate supernet-based search.

A Gradient-guided Evolutionary Neural Architecture Search
GENAS combines evolutionary search with gradient-guided local refinement in a weight-sharing supernet. The method keeps the exploration strength of evolutionary NAS while using efficient local updates to improve candidate architectures without retraining every subnet from scratch.

Self-adaptive Weight Based on Dual-attention for Differentiable Neural Architecture Search
SWD-NAS stabilizes differentiable neural architecture search with a dual-attention mechanism that reweights candidate operations more reliably than vanilla architecture parameters, reducing the bias and collapse behaviors often observed in DARTS-style search.
Earlier Publications
Service and Recognition
I serve as a reviewer for IEEE Transactions on Neural Networks and Learning Systems, IEEE Transactions on Circuits and Systems for Video Technology, Swarm and Evolutionary Computation, Scientific Reports, and Knowledge Engineering Review.
Recent awards include the National Scholarship, the NUIST Graduate "Puxin" Elite Scholarship, the Principal Scholarship, and the First Prize Scholarship in 2024.